
Why Hadoop is Vital? Key Reasons To Learn Hadoop
In the current fast-paced world, we hear a term – Big Data. Nowadays various companies collect data posted online. This unstructured data found on websites like Facebook, Instagram, emails, etc comprise Big Data. Big Data demands an economical, innovative solution to store and evaluate it. Hadoop is the key to all Big Data requirements. So, let’s explore why Hadoop is so important.

Why Hadoop is Important?
Below is the list of features that will explain Why Hadoop is important?
1. Managing Big Data
As we live within the digital era there’s a data explosion. the data is getting generated at a high speed and high volume. So there’s an increasing requirement to manage this Big Data.
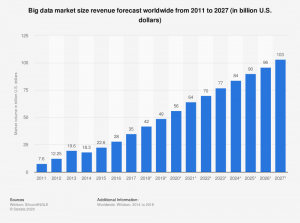
Image Source: Statista
As we can see from the above chart that the volume of unstructured data is increasing exponentially. Hence to manage this ever-increasing volume of data, we require Big Data technologies like Hadoop. According to Google from the dawn of civilization till 2003 mankind generated 5 exabytes of data. Now we produce 5 exabytes every two days. There is an increasing need for a solution that could handle this much amount of data. In this scenario, Hadoop comes to rescue.
With its robust architecture and economical feature, it is the best fit for storing huge amounts of data.
So Hadoop must be learned by all those professionals willing to start a career in big data as it is the base for all big data jobs.
2. Exponential Growth of Big Data Market
“Hadoop Market is estimated to reach $87.14B by 2022 at a CAGR of 42.1%” – Forbes
Gradually companies are realizing the advantage big data can bring to their business. The big data analytics segment in India will grow eightfold. As per NASSCOM, it will reach USD 16 billion by 2025 from USD 2 billion. As India advances, there is a penetration of smart devices in cities and villages. This will scale up the big data market.
As we can look at the below image there is a growth in the Hadoop market.
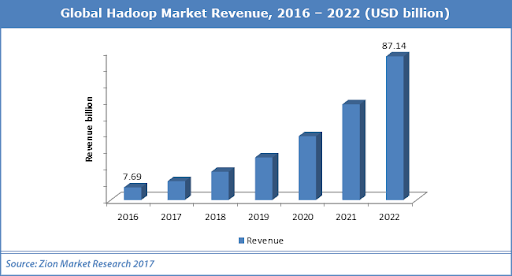
There is a prediction that the Hadoop market will grow at a CAGR of 58.02% from 2013 to 2020. It will reach $50.2 billion by 2020 from $1.5 billion in 2012.
As the market for Big Data grows there will be a rising need for Big Data technologies. Hadoop forms the base of the many big data technologies. The new technologies like Apache Spark and Flink work over Hadoop. As it is an in-demand big data technology, there’s a requirement to master Hadoop. As the requirements for Hadoop professionals are increasing, this makes it a requirement to find out the technology.
3. Lack of Hadoop Professionals
As we have seen, the Hadoop market is continuously growing to create more job opportunities every day. Most of these Hadoop job opportunities remain vacant due to the unavailability of the required skills. So this is the right time to show your talent in big data by mastering the technology before its too late. Become a Hadoop specialist and give an uplift to your career. This is where we play an important role to make you a Hadoop expert.
4. Hadoop for all
Professionals from various streams can easily learn Hadoop and become master of it to get high paid jobs. IT professionals can easily learn MapReduce programming in java or python, those who know scripting can work on the Hadoop ecosystem component named Pig. Hive or drill is simple for those who know the script.
You can easily learn it if you are:
- IT Professional
- Testing professional
- Mainframe or support engineer
- DB or DBA professional
- Graduate eager to start a career in big data
- Data warehousing professional
- The project manager or lead
5. Robust Hadoop Ecosystem
Hadoop features a very robust and rich ecosystem that serves a good sort of organization. Organizations like web start-ups, telecom, financial then on are needing Hadoop to answer their business needs.
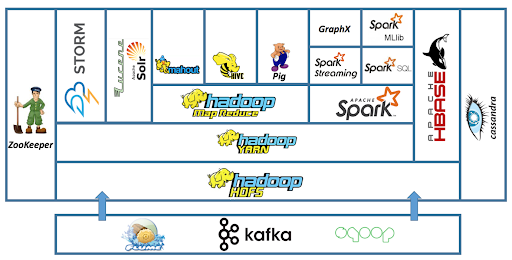
Hadoop ecosystem contains several components like MapReduce, Hive, HBase, Zookeeper, Apache Pig, etc. These components can serve a broad spectrum of applications. Map-Reduce can be used to perform aggregation and summarization on Big Data. Hive may be a data warehouse project on the highest HDFS. Hive provides data query and analysis with SQL like interface. HBase is a NoSQL database. It provides real-time read-write to large datasets. It is natively integrated with Hadoop. The pig may be a high-level scripting language used with Hadoop. It describes the data analysis problem as data flows. One can do all the info manipulation in it with Pig. Zookeeper is an open-source server that coordinates between various distributed processes. Distributed applications use zookeeper to store and convey updates to big configuration information.
6. Research Tool
Hadoop has come about as a powerful research tool. It allows an organization to find answers to their business questions. Hadoop helps them in research and development work. Companies use it to perform the analysis. They use this analysis to develop a rapport with the customer.
Applying Big Data techniques enhance operational effectiveness and efficiencies of generating great revenue in business. It brings a better understanding of the business value and develops business growth. Communication and distribution of information between different companies are feasible via big data analytics and IT techniques. The organizations can collect data from their customers to grow their business.
7. Ease of Use
Hadoop has been written in Java, which has the biggest developer community. Therefore, it is easy to adapt by programmers. You can have the pliability of programming in other languages too like C, C++, Python, Perl, Ruby, etc. If you’re conversant in SQL, it’s easy to use HIVE. If you’re comfortable with scripting then PIG is for you.
Hadoop framework handles all the multiprocessing of the data at the back-end. We need not worry about the complexities of distributed processing while coding. We just need to write the driver program, mapper, and reducer function. Hadoop framework takes care of how the info gets stored and processed during a distributed manner. With the initiation of Spark in Hadoop, ecosystem coding has become even easier. In MapReduce, we need to write thousands of lines of code. But in Spark, it has come down to only a few lines of code to achieve the same functionality.
8. Hadoop is Universal
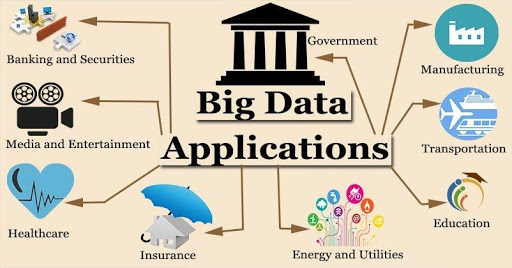
There is no industry that Big Data has not reached. Big Data has covered most domains like healthcare, retail, government, banking, media, transportation, natural resources than on. We can see this in the figure above. People are increasingly becoming data-aware. This means they are realizing the power of data. Hadoop is a framework that can harness this power of data to improve the business.
Companies all over the world are trying to access information from various sources like social media. They are doing so to improve their performance and increase their revenue. Many organizations face problems in processing assorted data to extract value out of it. It can guide revolutionary transformation in research, invention, and business marketing.
Big names like Walmart, NY Times, Facebook, etc are all using the Hadoop framework for his or her companies and thus demand a really good number of Hadoop experts. So become Hadoop expert now before its too late to get a job in your dream company.
9. Higher Salaries
In the present scenario, there is a gap between demand and supply of Big Data professionals. This gap is increasing every day. As per IBM, demand for US data professionals will reach to 364000 by 2020. In the wake of the scarcity of Hadoop professionals, organizations are ready to offer big packages for Hadoop skills. As per reality, the average salary for Hadoop skills is $112,000 per annum. It is 95% higher than the average salaries for all other job postings. There is always a compelling requirement of skilled people who can think from a business point of view. Hadoop professionals are the people who understand data and can produce insights with that data. For this reason, technical persons with analytics skills find them in huge demand.
10. A Growing Technology
Hadoop is evolving with time. The new version of Hadoop i.e. Hadoop 3.0 is coming into the market. It has already collaborated with HortonWorks, Tableau, MapR, and even BI experts to call a couple of. New actors like Spark, Flink, etc. are coming on the Big Data stage. These technologies promise the lightening speed of processing. These technologies also provide one platform for various sorts of workloads. It is compatible with these new players. It provides robust data storage over which we will deploy technologies like Spark and Flink.
The arrival of Spark has advanced the Hadoop ecosystem. The coming of Spark within the market has enriched the processing capability of Hadoop. Spark creators have designed it to work with Hadoop’s distributed storage system HDFS. It can also work over HBase and Amazon’s S3. Even if you work on Hadoop 1.x you can take advantage of Spark’s capabilities.
The newest technology Flink also provides compatibility with Hadoop. You can use all the Map-Reduce APIs in Flink without changing a line of code. Flink also supports local Hadoop datatypes like Writable and WritableComparable. We can use Hadoop functions within the Flink program. We can mix Hadoop functions with all the other Flink functions.
11. Hadoop has a Better Career Scope
Hadoop excels in processing a good sort of data. We have various components of the Hadoop ecosystem providing execution, stream processing, machine learning than on. Learning it’ll open gates to a spread of job roles like:
- Big Data Architect
- Hadoop Developer
- Data Scientist
- Hadoop Administrator
- Data Analyst
By learning Hadoop you can get into the hottest field in IT nowadays. Even a fresher can get into this field with proper training and hard work. People already within the IT industry working as ETL, architect, mainframe professional than on having a foothold over freshers. But with a determination, you’ll build your career as a Hadoop professional. Companies use it almost altogether domains like education, health care, insurance, and so on. This enhances the chances of getting placed as a Hadoop professional.
Fortune 1000 companies are adopting Big Data for companies growing business needs. Here is the status of big data adoption across various organizations –
- 12% of big data initiatives are under consideration
- 17% of big data initiatives are underway
- 67% of big data in production
From the above statistics, it’s clear that the adoption of Hadoop is accelerating. This is creating an enormous demand for Hadoop professionals with a high salary bracket.
As said by Christy Wilson Hadoop is the way of the long run. This is because companies aren’t getting to be ready to remain competitive without the facility of big data. And there no viable, affordable options apart from Hadoop.
I hope you got the answer to why Hadoop.
Summary
Hence, during this why Hadoop article, we saw that this is often the age of emerging technologies and hard competitions. The best way to shine is to have a solid understanding of the skill in which you want to build your career. Instructor-led online training is beneficial for learning Big Data technology. Also, the training with hands-on projects would provide a good grip on the technology. Hadoop started with just two components i.e. HDFS and MapReduce. As time passed more than 15 components got added to the Hadoop ecosystem and it is still growing. Studying these old components helps in understanding the newly added components.