
In this lesson, we will learn completely about MapReduce Shuffling and Sorting. Here we will offer you a detailed description of the Hadoop Shuffling and Sorting phase. Initially, we will discuss what is MapReduce Shuffling, next with MapReduce Sorting, then we will discuss MapReduce the secondary sorting phase in detail.
What is MapReduce Shuffling and Sorting?
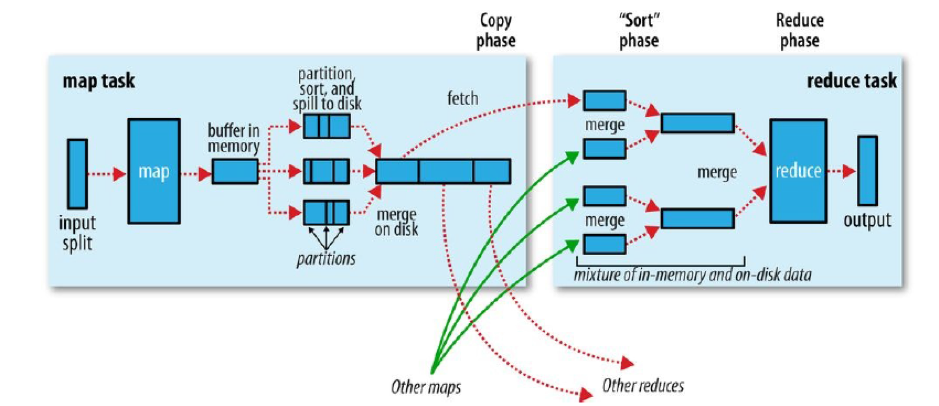
Shuffling is the process by which it transfers the mapper’s intermediate output to the reducer. Reducer gets one or more keys and associated values based on reducers. The intermediated key – value generated by the mapper is sorted automatically by key. In Sort phase merging and sorting of the map, the output takes place.
Shuffling and Sorting in Hadoop occur simultaneously.
Shuffling in MapReduce
The process of moving data from the mappers to reducers is shuffling. Shuffling is also the process by which the system performs the sort. Then it moves the map output to the reducer as input. This is the reason the shuffle phase is required for the reducers. Else, they would not have any input (or input from every mapper). Meanwhile, shuffling can begin even before the map phase has finished. Therefore this saves some time and completes the tasks in lesser time.
Sorting in MapReduce
MapReduce Framework automatically sorts the keys generated by the mapper. Therefore, before starting of reducer, all intermediate key-value pairs get sorted by key and not by value. It does not sort values transferred to each reducer. They can be in any order.
Sorting in a MapReduce job helps reducer to easily differentiate when a new reduce task should start. This saves time for the reducer. Reducer in MapReduce begins a new reduce task when the next key in the sorted input data is different from the earlier. Each reduce task takes key-value pairs as input and creates a key-value pair as output.
The crucial thing to note is that shuffling and sorting in Hadoop MapReduce is will not take place at all if you specify zero reducers (setNumReduceTasks(0)). If the reducer is zero, then the MapReduce job stops at the map phase. And the map phase does not comprise any kind of sorting (even the map phase is faster).
Secondary Sorting in MapReduce
If we need to sort reducer values, then we use a secondary sorting technique. This technique allows us to sort the values (in ascending or descending order) transferred to each reducer.
Conclusion
In conclusion, MapReduce Shuffling and Sorting takes place simultaneously to summarize the Mapper intermediate output. Hadoop Shuffling-Sorting will not occur if you state zero reducers (setNumReduceTasks (0)). The framework sorts all intermediate key-value pairs by key, not by value. It uses secondary sorting for sorting by value.