
Flipkart the World’s number one e-commerce platform is using analytics and algorithms to get better insights into its business during any type of sale or festival season. This article will explain to you how the Flipkart is leveraging Big Data Platform for processing big data in streams and batches. This service-oriented architecture empowers user experience, optimizes logistics, and improves product listings. It will give you an insight into how this ingenious big data platform can process such large amounts of data. Before starting, I recommend you to check this Big Data guide to better understand its core concepts.
Big Data at Flipkart
Flipkart Data Platform is a service-oriented architecture that is capable of computing batch data as well as streaming data. This platform comprises of various micro-services that promote user experience through efficient product listings, optimization of prices, maintaining various types of data domains – Redis, HBase, SQL, etc. This FDP is capable of storing 35 PetaBytes of data and is capable of managing 800+ Hadoop nodes on the server. This is just a brief of how Big Data is helping Flipkart. Below I am sharing a detailed explanation of Flipkart data platform architecture that will help you to understand the process better.
The Architecture of Flipkart Data Platform
To know how Flipkart is using Big Data, you would like to know the flow of knowledge or Flipkart’s data platform architecture which is explained through the below flow chart-
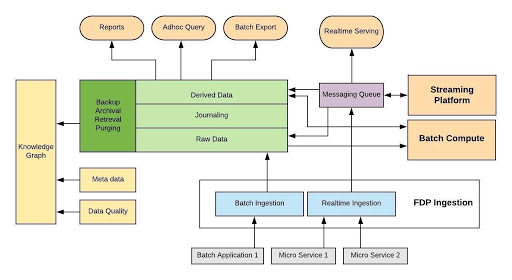
How Big Data is helping Flipkart?
Let’s take a tour of the complete process of how Flipkart works on Big Data.
1. FPD Ingestion System
A Big Data Ingestion System is the first place where all the variables start their journey into the info system. it’s a process that involves the import and storage of information in a database. This data can either be taken within the sort of batches or real-time streams. Simply speaking, batch consists of a set of knowledge points that are grouped during a specific interval. On the contrary, streaming data has got to affect the endless flow of data. Batch Data has greater latency than streaming data which is a smaller amount than sub-seconds. There are 3 ways during which ingestion are often performed –
• Specter – this is often a Java library that’s used for sending the draft to Kafka.
• Dart Service – this is often a REST service which allows the payload to be sent over HTTP.
• File Ingestor – With this, we will make use of the CLI tool to dump data into the HDFS.
Then, the user creates a schema that the corresponding Kafka topic is made. Using Specter, data is then ingested into the FDP. The payload within the HDFS file is stored within the sort of HIVE tables.
2. Batch Compute
This part of the big data ecosystem is used for computing and processing data that is present in batches. Batch Compute is an efficient method for processing large scale data that is present in the form of transactions that are collected over some time. These batches can be computed at the end of the day when the data is collected in large volumes, only to be processed once. This is the time you need to explore Big Data as much as possible. Here is the free Big Data tutorials series which will help you to master the technology.
3. Streaming Platform
The streaming platforms process the data that is generated in sub-seconds. Apache Flink is one of the most popular real-time streaming platforms that are used to produce fast-paced analytical results. It provides a distributed, fault-tolerant, and scalable data streaming capabilities that can be used by the industries to process a million transactions at one time without any latency.
4. Messaging Queue
A Messaging Queue acts like a buffer or a temporary storage system for messages when the destination is busy or not connected. The message can be in the form of a plain message, a byte array consisting of headers, or a prompt that commands the messaging queue to process a task. There are two components in the Messaging Queue Architecture – Producer and Consumer. A Producer generates the messages and delivers them to the messaging queue. A Consumer is the end destination of the message where the message is processed.
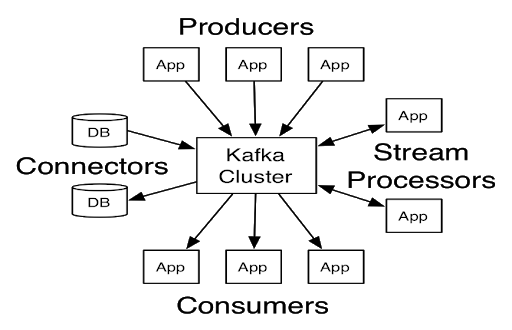
The most popular tool used in Messaging Queues is Kafka. Apache Kafka is an open-source stream-processing software system that is heavily inspired by the transaction logs. A large number of companies around the world make use of Kafka as their primary platform for buffering messages. Its scalability, zero fault tolerance, reliability, and durability make it an ideal choice for industry professionals.
5. Real-time Serving
After the messages are retrieved from the Messaging Queue, the real-time serving system acts as a consumer for the messaging queue. With the help of this real-time serving platform, users can gather real-time insights from the data platform. Furthermore, with the help of real-time serving, the users can access the data through dynamic pipelines.
6. Data Lake
The core component of this architecture is the data storage platform. The data storage platform is a Hadoop platform that stores raw data, journaled data as well as derived data. Using this, the data is stored in the form of a backup, archive that can be retrieved or purged according to the requirements. The raw data is mostly used by the data scientists who use the insights from the original data to make decisions and develop data products. The data is present in the form of batches or real-time streams. The real-time data is in the form of clickstreams, summarized reports of user data, product insights, reviews, etc.
From the data lake, data is transferred to three main routes –
a. reports
The reports are generally produced from the batch data. These reports allow a comprehensive insight into website logs, daily website readings, and other forms of reports. With the help of these reports, companies like Flipkart can quantify the market needs as well.
b. Ad hoc Query
Ad hoc Query is designed for some specific purpose or use. The Adhoc Queries that are generated from the data-lake are handled by the data analysts. These data analysts make use of various business intelligence tools to discover meaning from the data.
c. Batch Export
This part of the data platform takes the data from data-lake and exports it in various formats to the further processing platforms. The data is present in huge bulks that are exported.
d. Knowledge Graphs
Knowledge graphs represent an interlinked network of real-world entities or objects through which we can extract information to process it efficiently. This knowledge graph takes input from the meta-data. This metadata is beneficial for understanding the underlying semantics which is used for deriving newer facts. The knowledge graph also makes use of various machine learning tools and libraries to gain insights and understand the relationships between the objects. One of the most popular tools that are used for building a graph is Apache Spark’s GraphX library.
Summary
I hope now you understand how Big Data is helping Flipkart to offer the best services all around the World. In this article, we looked at the ingenious big data platform that is designed by Flipkart to handle large scale data transactions. We also understood how Flipkart makes use of various big data components to deliver dynamic results to the user. We also had a look at how the Big Data Platform is capable of processing large scale data queries that allow it to produce results