
In this tutorial, we will have an overview of various Hadoop Ecosystem Components. These ecosystem components are different services deployed by the various enterprise. We can integrate these to work with a variety of data. Each of the Hadoop Ecosystem Components is developed to deliver precise functions. Besides, each has its developer community and individual release cycle.
So, let us explore Hadoop Ecosystem Components.
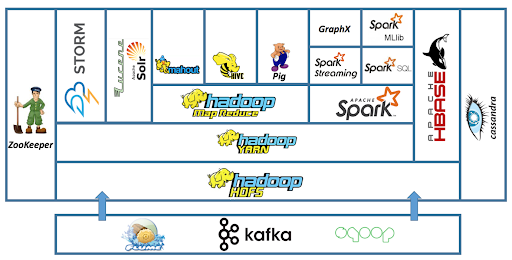
Hadoop Ecosystem Components
Hadoop Ecosystem is a suite of services that work to solve the Big Data problem. The different components of the Hadoop Ecosystem are as follows:-
1. Hadoop Distributed File System Component

HDFS is the foundation of Hadoop and hence is a very important component of the Hadoop ecosystem. It is Java software that provides many features like scalability, high availability, fault tolerance, cost-effectiveness, etc. It also provides robust distributed data storage for Hadoop. We can deploy many other software frameworks over HDFS.
Major Components of HDFS:
There are three major components of Hadoop HDFS are as follows:-
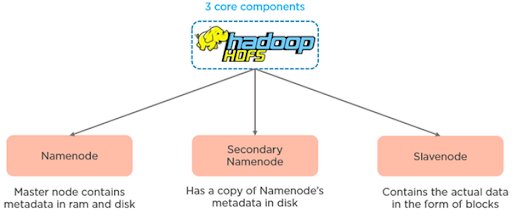
a. DataNode
These are the nodes that store the actual data. HDFS stores the data in a distributed manner. It divides the input files of varied formats into blocks. The DataNodes stores each of these blocks. Following are the functions of DataNodes:-
- On startup, DataNode does handshake with NameNode. It verifies the namespace ID and software version of DataNode.
- Also, it sends a block report to NameNode and verifies the block replicas.
- It sends a heartbeat to NameNode every 3 seconds to tell that it is alive.
b. NameNode
NameNode is nothing but the master node. The NameNode is responsible for managing file system namespace, controlling the client’s access to files. Also, it executes tasks such as opening, closing, and naming files and directories. NameNode has two major files – FSImage and Edits log
FSImage – FSImage is a point-in-time snapshot of HDFS’s metadata. It contains information like file permission, disk quota, modification timestamp, access time, etc.
Edits log – It contains modifications on FSImage. It records incremental changes like renaming the file, appending data to the file, etc.
Whenever the NameNode starts it applies Edits log to FSImage. And the new FSImage gets loaded on the NameNode.
c. Secondary NameNode
If the NameNode has not restarted for months the size of Edits log increases. This, in turn, increases the downtime of the cluster on the restart of NameNode. In this case, Secondary NameNode comes into the picture. The Secondary NameNode applies edits log on FSImage at regular intervals. And it updates the new FSImage on primary NameNode.
2. MapReduce Component
![]()
MapReduce is the data processing component of Hadoop. It applies the computation on sets of data in parallel thereby improving the performance. MapReduce works in two phases –
Map Phase – This phase takes input as key-value pairs and produces output as key-value pairs. It can write custom business logic in this phase. The map phase processes the data and gives it to the next phase.
Reduce Phase – The MapReduce framework sorts the key-value pair before giving the data to this phase. This phase applies the summary type of calculations to the key-value pairs.
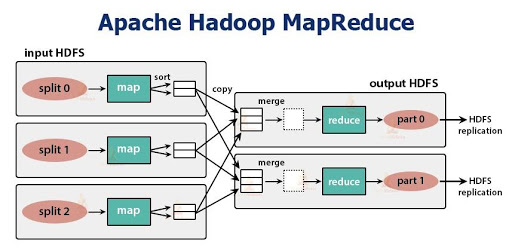
- Mapper reads the block of data and converts it into key-value pairs.
- Now, these key-value pairs are input to the reducer.
- The reducer receives data tuples from multiple mappers.
- Reducer applies aggregation to these tuples based on the key.
- The final output from the reducer gets written to HDFS.
MapReduce framework takes care of the failure. It recovers data from another node in an event where one node goes down.
3. YARN Component
![]()
The yarn is short for Yet Another Resource Manager. It is like the operating system of Hadoop as it monitors and manages the resources. The yarn came into the picture with the launch of Hadoop 2.x to allow different workloads. It handles the workloads like stream processing, interactive processing, batch processing over a single platform. The yarn has two main components – Node Manager and Resource Manager.
a. Node Manager
It is Yarn’s per-node agent and takes care of the individual compute nodes in a Hadoop cluster. It monitors the resource usage like CPU, memory, etc. of the local node and intimates the same to Resource Manager.
b. Resource Manager
It is responsible for tracking the resources in the cluster and scheduling tasks like map-reduce jobs.
Also, we have the Application Master and Scheduler in Yarn. Let us take a look at them.
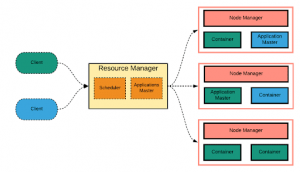
Application Master has two functions and they are:-
- Negotiating resources from Resource Manager
- Working with NodeManager to monitor and execute the sub-task.
Following are the functions of Resource Scheduler:-
- It allocates resources to various running applications
- But it does not monitor the status of the application. So in the event of failure of the task, it does not restart the same.
We have another concept called Container. It is nothing but a fraction of NodeManager capacity i.e. CPU, memory, disk, network, etc.
4. Hive Component
![]()
Hive is a data warehouse project built on the top of Apache Hadoop which provides data queries and analysis. It has got the language of its call HQL or Hive Query Language. HQL automatically translates the queries into the corresponding map-reduce job.
Main parts of the Hive are –
- MetaStore – it stores metadata
- Driver – Manages the lifecycle of HQL statement
- Query compiler – Compiles HQL into DAG i.e. Directed Acyclic Graph
- Hive server – Provides interface for JDBC/ODBC server.
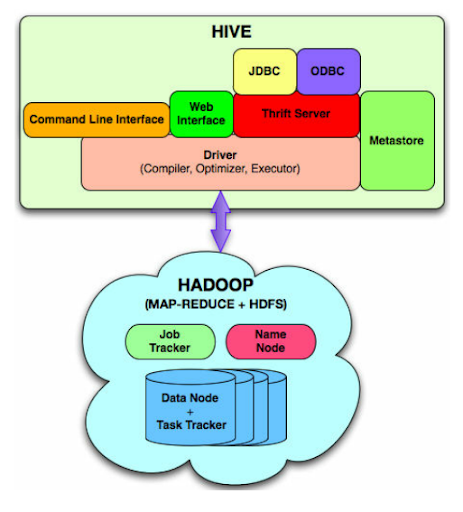
Facebook designed Hive for people who are comfortable in SQL. It has two basic components – Hive Command-Line and JDBC, ODBC. Hive Command line is an interface for the execution of HQL commands. And JDBC, ODBC establishes the connection with data storage. Hive is highly scalable. It can handle both types of workloads i.e. batch processing and interactive processing. It supports native data types of SQL. Hive provides many pre-defined functions for analysis. But you can also define your custom functions called UDFs or user-defined functions.
5. Apache Pig Component
![]()
Pig is a SQL like a language used for querying and analyzing data stored in HDFS. Yahoo was the original creator of the Pig. It uses pig Latin language. It loads the data, applies a filter to it, and dumps the data in the required format. Pig also consists of JVM called Pig Runtime. Various features of Pig are as follows:-
- Extensibility – For carrying out special-purpose processing, users can create their custom functions.
- Optimization opportunities – Pig automatically optimizes the query allowing users to focus on semantics rather than efficiency.
- Handles all kinds of data – Pig evaluates both structured as well as unstructured.
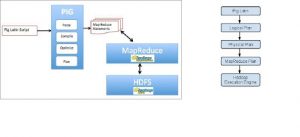
a. How does Pig work?
- First, the load command loads the data.
- At the backend, the compiler converts pig Latin into the sequence of map-reduce jobs.
- Over this data, we perform various functions like joining, sorting, grouping, filtering, etc.
- Now, you can dump the output on the screen or store it in an HDFS file.
6. HBase Component
![]()
HBase is a NoSQL database built on the top of HDFS. The various features of HBase are that it is an open-source, non-relational, distributed database. It imitates Google’s Bigtable and written in Java. It provides real-time read/write access to large datasets. Its various components are as follows:-
a. HBase Master
HBase performs the following functions:
- Maintain and monitor the Hadoop cluster.
- Performs administration of the database.
- Controls the failover.
- HMaster handles DDL operations.
b. RegionServer
Region server is a process that handles read, writes, update, and delete requests from clients. It runs on every node in a Hadoop cluster that is HDFS DataNode.
HBase is a column-oriented database management system. It runs on top of HDFS. It suits for sparse data sets which are common in Big Data use cases. HBase supports writing an application in Apache Avro, REST, and Thrift. Apache HBase has low latency storage. Enterprises use this for real-time analysis.
The design of HBase is such that to contain many tables. Each of these tables must have a primary key. Access attempts to HBase tables use this primary key.
As an example lets us consider HBase table storing diagnostic log from the server. In this case, the typical log row will contain columns such as timestamps when the log gets written. And server from which the log originated.
7. Mahout Component
![]()
Mahout provides a platform for creating machine learning applications that are scalable.
a. What is Machine Learning?
Machine learning algorithms allow us to create self-evolving machines without being explicitly programmed. It makes future decisions based on user behavior, past experiences, and data patterns.
b. What Mahout does?
It performs collaborative filtering, clustering, and classification.
- Collaborative filtering – Mahout mines user behavior patterns and based on these it makes recommendations to users.
- Clustering – It groups together a similar type of data like the article, blogs, research paper, news, etc.
- Classification – It means categorizing data into various sub-departments. For example, we can classify articles into blogs, essays, research papers, and so on.
- Frequent Itemset missing – It looks for the items generally bought together and based on that it gives a suggestion. For instance, usually, we buy a cell phone and its cover together. So, when you buy a cell phone it will suggest buying a cover also.
8. Zookeeper Component
![]()
Zookeeper coordinates between various services in the Hadoop ecosystem. It saves the time required for synchronization, configuration maintenance, grouping, and naming. Following are the features of Zookeeper:-
- Speed – Zookeeper is fast in workloads where reads to data are more than write. A typical read: write ratio is 10:1.
- Organized – Zookeeper maintains a record of all transactions.
- Simple – It maintains a single hierarchical namespace, similar to directories and files.
- Reliable – We can replicate Zookeeper over a set of hosts and they are aware of each other. There is no single point of failure. As long as major servers are available zookeeper is available.
Why do we need Zookeeper in Hadoop?
Hadoop faces many problems as it runs a distributed application. One of the problems is the deadlock. Deadlock occurs when two or more tasks fight for the same resource. For instance, task T1 has resource R1 and is waiting for resource R2 held by task T2. And this task T2 is waiting for resource R1 held by task T1. In such a scenario deadlock occurs. Both task T1 and T2 would get locked waiting for resources. Zookeeper solves the Deadlock condition via synchronization.
Another problem is the race condition. This occurs when the machine tries to perform two or more operations at a time. Zookeeper solves this problem by property of serialization.
9. Oozie Component
![]()
It is a workflow scheduler system for managing Hadoop jobs. It supports Hadoop jobs for Map-Reduce, Pig, Hive, and Sqoop. Oozie combines multiple jobs into a single unit of work. It is scalable and can manage thousands of workflows in a Hadoop cluster. Oozie works by creating DAG i.e. Directed Acyclic Graph of the workflow. It is very much flexible as it can start, stop, suspend, and rerun failed jobs.
Oozie is an open-source web-application written in Java. Oozie is scalable and can execute thousands of workflows containing dozens of Hadoop jobs.
There are three basic types of Oozie jobs and they are as follows:-
- Workflow – It stores and runs a workflow composed of Hadoop jobs. It stores the job as Directed Acyclic Graph to determine the sequence of actions that will get executed.
- Coordinator – It runs workflow jobs based on predefined programs and the availability of data.
- Bundle – This is nothing but a package of many coordinators and workflow jobs.
How does Oozie work?
Oozie runs a service in the Hadoop cluster. The client submits the workflow to run, immediately or later.
There are two types of nodes in Oozie. They are action nodes and control flow-node.
- Action Node – It represents the task in the workflow like MapReduce job, shell script, pig or hive jobs, etc.
- Control flow Node – It controls the workflow between actions by employing conditional logic. In this, the previous action decides which branch to follow.
Start, End, and Error Nodes fall under this category.
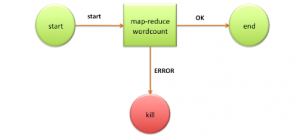
- Start Node signals the start of the workflow job.
- End Node designates the end of the job.
- ErrorNode signals the error and gives an error message.
10. Sqoop Component
![]()
Sqoop imports data from external sources into compatible Hadoop Ecosystem components like HDFS, Hive, HBase, etc. It also transfers data from Hadoop to other external sources. It works with RDBMS like Teradata, Oracle, MySQL, and so on. The major difference between Sqoop and Flume is that Flume does not work with structured data. But Sqoop can deal with structured as well as unstructured data.
Let us see how Sqoop works
When we submit Sqoop command, at the back-end, it gets divided into several sub-tasks. These sub-tasks are nothing but map-tasks. Each map-task import a part of data to Hadoop. Hence all the map-task taken together imports the whole data.
Sqoop export also works similarly. The only thing is instead of importing, the map-task export the part of data from Hadoop to the destination database.
11. Flume Component
![]()
It is a service that helps to ingest structured and semi-structured data into HDFS. Flume works on the principle of distributed processing. It aids in collection, aggregation, and movement of a huge amount of data sets. Flume has three components source, sink, and channel.
Source – It accepts the data from the incoming stream and stores the data in the channel
Channel – It is a medium of temporary storage between the source of the data and persistent storage of HDFS.
Sink – This component collects the data from the channel and writes it permanently to the HDFS.
12. Ambari Component
![]()
Ambari is another Hadoop ecosystem component. It is responsible for provisioning, managing, monitoring, and securing the Hadoop cluster. Following are the different features of Ambari:
- Simplified cluster configuration, management, and installation
- Ambari reduces the complexity of configuring and administration of Hadoop cluster security.
- It ensures that the cluster is healthy and available for monitoring.
Ambari gives:-
Hadoop cluster provisioning
- It gives step by step procedure for installing Hadoop services on the Hadoop cluster.
- It also handles the configuration of services across the Hadoop cluster.
Hadoop cluster management
- It provides centralized service for starting, stopping, and reconfiguring services on the network of machines.
Hadoop cluster monitoring
- To monitor health and status Ambari provides us dashboard.
- Ambari alert framework alerts the user when the node goes down or has low disk space etc.
13. Apache Drill Component
![]()
Apache Drill is a schema-free SQL query engine. It works on the top of Hadoop, NoSQL and cloud storage. Its main purpose is large scale processing of data with low latency. It is a distributed query processing engine. We can query petabytes of data using Drill. It can scale to several thousands of nodes. It supports NoSQL databases like Azure BLOB storage, Google cloud storage, Amazon S3, HBase, MongoDB, and so on.
Let us look at some of the features of Drill:-
- A variety of data sources can be the basis of a single query.
- The Drill follows ANSI SQL.
- It can support millions of users and serve their queries over large data sets.
- Drill gives faster insights without ETL overheads like loading, schema creation, maintenance, transformation, etc.
- It can analyze multi-structured and nested data without having to do transformations or filtering.
14. Apache Spark Component
![]()
Apache Spark unifies all kinds of Big Data processing under one umbrella. It has built-in libraries for streaming, SQL, machine learning, and graph processing. Apache Spark is lightning fast. It gives good performance for both batch and stream processing. It does this with the help of DAG scheduler, query optimizer, and physical execution engine.
Spark offers 80 high-level operators which makes it easy to build parallel applications. Spark has various libraries like MLlib for machine learning, GraphX for graph processing, SQL and Data frames, and Spark Streaming. One can run Spark in standalone cluster mode on Hadoop, Mesos, or on Kubernetes. One can write Spark applications using SQL, R, Python, Scala, and Java. As such Scala in the native language of Spark. It was originally developed at the University of California, Berkley. Spark does in-memory calculations. This makes Spark faster than Hadoop map-reduce.
15. Solr And Lucene Component

Apache Solr and Apache Lucene are two services that search and index the Hadoop ecosystem. Apache Solr is an application built around Apache Lucene. Code of Apache Lucene is in Java. It uses Java libraries for searching and indexing. Apache Solr is an open-source, blazing fast search platform.
Various features of Solr are as follows –
- Solr is highly scalable, reliable, and fault-tolerant.
- It provides distributed indexing, automated failover and recovery, load-balanced query, centralized configuration, and much more.
- You can query Solr using HTTP GET and receive the result in JSON, binary, CSV, and XML.
- Solr provides matching capabilities like phrases, wildcards, grouping, joining, and much more.
- It gets shipped with a built-in administrative interface enabling management of solr instances.
- It takes advantage of Lucene’s near real-time indexing. It enables you to see your content when you want to see it.
So, this was all in the Hadoop Ecosystem. I hope you liked this article.
Summary
The Hadoop ecosystem elements described above are all open system Apache Hadoop Project. Many commercial applications use these ecosystem elements. Let us summarize the Hadoop ecosystem components. At the core, we have HDFS for data storage, map-reduce for data processing, and Yarn a resource manager. Then we have HIVE a data analysis tool, Pig – SQL like a scripting language, HBase – NoSQL database, Mahout – machine learning tool, Zookeeper – a synchronization tool, Oozie – workflow scheduler system, Sqoop – structured data importing and exporting utility, Flume – data transfer tool for unstructured and semi-structured data, Ambari – a tool for managing and securing Hadoop clusters, and lastly Avro – RPC, and data serialization framework.